Discussing Machine Learning and Financial Services
It feels like fear around artificial intelligence is slightly receding and that the discussion has evolved toward what it can actually do now and its application in the current crop of technology companies. I, for one, welcome this new step in Machiavellianism from our machine overlords, well played, well played….

Machine learning is about learning, measured as an improvement of an output (From the good read: http://www.androidauthority.com/what-is-machine-learning-621659/)
“ A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
Machine learning comes in various shapes but broadly there are important distinctions between:
- supervised learning, in which the computer is given example inputs and desirable outputs, with the goal for the machine to learn how to map the two.
- unsupervised learning, in which the inputs are not characterized and the machine has to learn what characteristics of the inputs are linked to the desirable outputs.
It is also important to understand that desirable outputs are effectively formulated as algorithms. They are very diverse and not only depend on the problem but also the approach taken to solve it. For example the graph below gives a good overview of potential solutions to a regression analysis problem.

So how does a machine think? Very differently from us as its input are more constrained data sets and its outputs are driven by equations. For example, this is how a computer views a picture of a cat on a carpet in order to be able to classify it as such.

So what can you do with a machine able to understand inputs and find correlations? A lot:
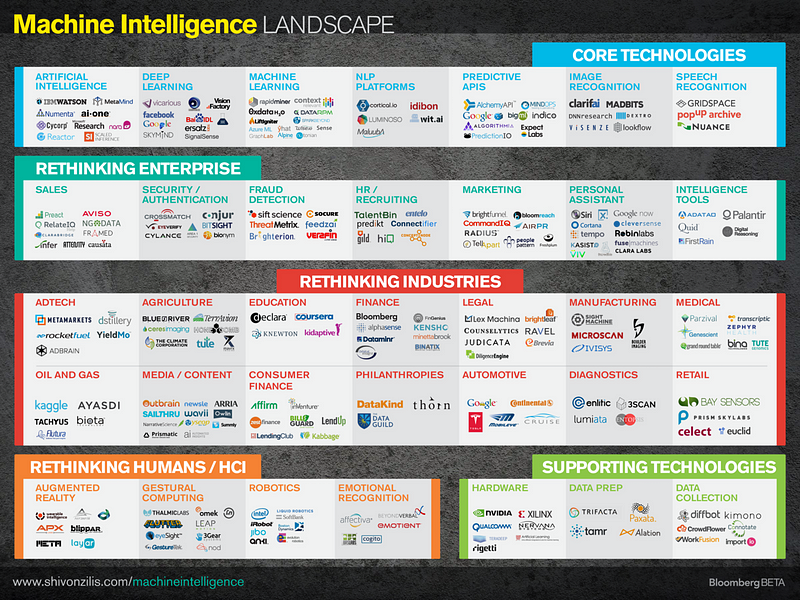
This map is already outdated increasingly, all businesses will leverage machine learning in some form and the infrastructure to do so is increasingly easier to access:
- IBM recently launched APIs to access Watson
- Google open sourced one of its core sofware Library for Machine Learning : Tensorflow
- Microsoft, just after Google announced its own open source release
- Machine learning is an increasing part of Amazon’s computing offer
It makes sense for these large players to open source a big part of their research and benefit from a broader development community. As we discussed above, an essential part of machine learning is gained from data and training, two components that remains firmly proprietary.
In Financial Services, in my mind there are short term two main cases for machine learning: one connected to the interface between humans and finance, the other to optimizing the analysis of vast pools of data.
One of my long standing pet peeve is the lack of innovation in building User Experience for Financial Services. Our representation paradigm is still too close to the accounting standard when only a very few % of the population receives the necessary education to understand those. Natural language interfaces are a rising tide for Financial services, because of their ability to abstract from pure financial data through a more intuitive user interface. This is true both for input and output. Two startups are a good example of this in my mind: Kensho and Narrative Science.
Facebook’s experimentation with M, is a strong indication of the future interface for financial services. Whether existing banks and financial services providers have the skill-set and ability to build and train these agents is an open question. Especially as AI has a strong lock-in effect.
On the data front, one of the key use of machine learning lies first with the ability to analyze at scale and speed data that would require an army of humans. A good example is satellite data. Companies such as Descartes Labs have the ability to determine crop type in satellite pictures of fields across massive sets of information. The other use case will most likely be understanding correlations in the large pool of digital breadcrumbs that people and companies increasingly create. Trading data, Credit scoring, because of their data rich outputs are prime targets. In credit scoring, one of the key concerns will be to make sure that these self learning algorithms comply with non discrimination laws.
Increasingly, if you are working on innovation in financial services and not actively looking into machine learning, you are probably doing it wrong.